
테키테크 TEKITECH
[Kafka Study] 04. 카프카의 내부 동작 원리와 구현 w/실전 카프카 개발부터 운영까지 본문
앞서 카프카의 기본 개념과 구조를 이해하고, 실습 환경을 구축해보았다. 이번 장에서는 카프카 기본 명령어를 사용해 실습을 진행하며 리플리케이션 동작과 리더-팔로워 역할, 리더에포크, 컨트롤러, 로그 및 로그 컴팩션 등 핵심 내부 동작의 원리를 공부해보려고 한다.
목차
- 카프카 리플리케이션
- 카프카의 기본 도구
- 토픽과 세그먼트, 그리고 리플리케이션
- [실습 1] kafka-topics.sh 명령어로 토픽 생성
- [실습 2] 토픽 상세 정보 확인
- [실습 3] 콘솔 프로듀서를 이용해 토픽에 메시지 전송
- [실습 4] 세그먼트 파일로 리플리케이션 확인
- 로그 세그먼트 관리 방법
- [실습 5] 로그 세그먼트 삭제
- 메세지 일관성 유지 전략
- 1. 리더-팔로워 역할 분리
- 2. ISR과 컨트롤러
- [실습 6] controlled shutdown 설정
- 3. 하이워터마크(커밋)와 리더에포크
- [실습 7] 하이워터마크 확인
- [실습 8] 리더에포크 확인

카프카 리플리케이션
카프카는 대량의 트래픽을 전송하는 환경에서도 높은 안정성과 최소한의 성능 저하를 유지한다. 이러한 카프카의 고가용성을 보장하는 가장 중요한 요소가 카프카의 리플리케이션 동작이다. 카프카 리플리케이션 동작을 이해하기 위해 알아야 하는 핵심 개념을 정리해보면 아래와 같다.
- 토픽Topic : 카프카에서 메시지 피드를 구분하기 위한 저장소
- 파티션Partition : 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것
- 리플리케이션Replication : 각 메시지들(파티션)을 여러 개로 복제해서 카프카 클러스터 내 다른 브로커에 분산시키는 동작
- 리플리케이션 팩터Replication Factor : 리플리케이션 동작 시 같은 메시지를 가지는 파티션의 총 개수 (= 원본 + 복제본)
- 최소 리플리케이션 수min.insync.replicas : 프로듀서가 acks 옵션을 all로 설정하여 메시지 전송 시, write 성공 확인을 위해 충족해야 하는 기준 (복제 완료 개수)
- 오프셋Offset : 파티션의 메시지가 저장되는 위치 (64bit 정수)
- 세그먼트Segment : 프로듀서가 전송한 메시지가 브로커의 로컬 디스크에 저장된 것
- 리더Leader : 리플리케이션 팩터 중 실제로 읽기와 쓰기 동작을 담당하는 파티션
- 팔로워Follower : 리더의 메시지를 복사하여 저장하는 파티션
- 컨트롤러Controller: ISR 관리와 리더 선출을 담당하는 브로커
- ISRInSyncReplica : 동일한 메시지를 갖고 있는 가용한 리더와 팔로워를 묶는 논리적 그룹
- 커밋Commit : ISR 내에서 모든 팔로워의 복제가 완료됨을 표시하는 동작
- 하이워터마크High Water Mark : 마지막 커밋 오프셋의 위치
- 리더에포크Leader Epoch : 컨트롤러가 과거에 선출했던 리더의 수 (32bit 정수)
카프카의 기본 도구
앞에서 카프카 메시징 테스트를 할 때 사용했던 kafka-topics.sh나 kafka-console-producer.sh와 같이 카프카를 사용할 때 주로 사용하는 기본 명령어가 있다. 그 중, 아래 5개가 주로 사용하는 명령어라고 한다.
- kafka-topics.sh: 토픽을 생성하거나 토픽 설정 등을 변경하기 위해 사용.
- kafka-console-producer.sh: 토픽으로 메시지를 전송하기 위해 사용.
- kafka-console-consumer.sh: 토픽에서 메시지를 가져오기 위해 사용.
- kadka-reassign-partitions.sh: 토픽의 파티션과 위치 변경 등을 위해 사용.
- kafka-dump-log.sh: 파티션에 저장된 로그 파일의 내용을 확인하기 위해 사용.
어떤 명령어가 있는지 궁금해서 bin 디렉토리를 찾아가 보니 뭐가 많이 있었다. 각 명령어는 실습하면서 천천히 알아갈 예정이다.

토픽과 세그먼트, 그리고 리플리케이션
일반적으로 프로듀서와 컨슈머는 카프카의 토픽 중 하나를 특정하여 메시지를 주고받는다. 토픽은 카프카의 기본 도구 중 하나인 kafka-topics.sh 명령어를 이용해서 생성할 수 있고, 토픽 생성 시 파티션의 수와 리플리케이션 팩터 수를 필수로 지정해주어야 한다. 처음에 설정한 파티션과 리플리케이션 팩터 수는 나중에 수정할 수 있지만, 파티션 수의 경우 늘릴 수는 있지만 줄일 수는 없다는 점에 주의해야 한다.
토픽을 생성한 후, 토픽 정보를 조회하여 토픽과 리플리케이션 등의 정보를 모니터링할 수 있다. 실습을 통해 리플리케이션을 기반으로 한 카프카의 장애 대응 로직을 알아보았다.
🐣 [실습 1] kafka-topics.sh 명령어로 토픽 생성
kafka-topics.sh는 토픽과 관련된 작업을 할 때 사용한다. 이 명령어를 사용해서 teki-test01라는 이름으로 토픽을 생성해주고, 생성한 토픽 정보를 확인해보았다.
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server teki-kafka01.foo.bar:9092 --create --topic teki-test01 --partitions 1 --replication-factor 3
Created topic teki-test01.
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server teki-kafka01.foo.bar:9092 --describe --topic teki-test01
Topic: teki-test01 PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: teki-test01 Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2# 토픽 생성 명령어
--bootstrap-server teki-kafka01.foo.bar:9092 : 토픽을 생성할 호스트 및 포트 지정
--create : 토픽에 대해 수행할 동작이 'create'임
--topic teki-test01 : 토픽의 이름을 지정 (teki-test01)
--partitions 1 : 토픽 내 파티션 개수를 지정 (1개)
--replication-factor 3 : 리플리케이션 팩터 개수를 지정 (3개)
# 토픽 정보 출력 명령어
--bootstrap-server teki-kafka01.foo.bar:9092 : 대상 토픽이 있는 서버의 호스트 및 포트 지정
--describe : 토픽에 대해 수행할 동작이 'describe'임
--topic teki-test01 : 토픽의 이름을 지정 (teki-test01)
🐣 [실습 2] 토픽 상세 정보 확인
describe 옵션으로 토픽 정보를 출력해서 파티션 수, 리플리케이션 팩터 수, 파티션 번호, 리더와 팔로워 번호 등을 확인할 수 있다.

# 토픽 정보
PartitionCount :1 : 해당 토픽 내에 파티션 개수가 1개임
ReplicationFactor: 3 : 해당 토픽에 리플리케이션 팩터가 3개임
Configs: segment.bytes=1073741824 : 세그먼트 파일 크기를 나타내며, default값이 1073741824(1GB)이다.
Topic: teki-test01 : 토픽 이름
Partition: 0 : 토픽 teki-test01 중 0번 파티션의 정보라는 표시
Leader: 1 : 파티션0의 리더가 브로커 1임을 나타냄
Replicas: 1,3,2 : 리플리케이션들이 브로커 1, 3, 2에 있음을 나타냄
Partition: 0 : 토픽 teki-test01 중 0번 파티션의 정보라는 나타냄
I sr: 1, 3, 2 : 현재 ISR 그룹에 속한 리플리케이션, 즉 현재 정상적으로 동기화되고 있는 리플리케이션을 나타냄.
🐣 [실습 3] 콘솔 프로듀서를 이용해 토픽에 메시지 전송
kafka-console-producer.sh 명령어로 CLI 창에서 토픽에 메시지를 전송할 수 있다. 명령어를 실행해주면 아래와 같이 메시지 입력 쉘이 활성화된다. 메시지를 받아서 확인할 필요는 없으니 컨슈머는 따로 띄우지 않고 이대로 테스트 메시지를 보내주었다.

🐣 [실습 4] 세그먼트 파일로 리플리케이션 확인
물리적으로 메시지 데이터는 세그먼트 파일(xxx.log)로 저장된다. 로그 파일이 있는 /data/kafka-logs 디렉토리를 보니 또 뭐가 많다.. 컨슈머 그룹 정보를 저장하는 카프카의 내부 토픽(__consumer_offset_xx)과 3장에서 만들었던 teki-overview01 토픽, 그리고 조금 전 만들었던 teki-test01 토픽을 확인할 수 있다.

토픽 이름 뒤에 붙은 숫자가 뭔지 궁금해서 확인해보니 파티션 번호라고 한다. 다른 브로커에서도 똑같이 저장돼있다.

토픽은 메시지 데이터를 정해진 크기(log.segment.bytes)로 나누어 저장하며, 각 세그먼트에서 첫 번째 레코드의 오프셋이 해당 세그먼트 파일의 이름이 된다. 이러한 세그먼트는 각각 .log, .index, .timeindex 등 세 가지 파일로 구성된다. 이들은 대용량의 메시지 데이터를 다루는 데 있어 비용을 줄이는 데 도움이 된다. 예를 들어, 대용량 파일에서 특정 오프셋을 찾아서 메시지를 읽어야 할 때 .index 파일을 이용해서 비용을 줄일 수 있다.

# 세그먼트 파일 종류
.log : 오프셋, 메시지의 물리적 위치, 메시지 내용 등 저장
.index : 오프셋에 물리적 위치를 매핑한 값
.timeindex : 오프셋에 timestamp를 매핑한 값
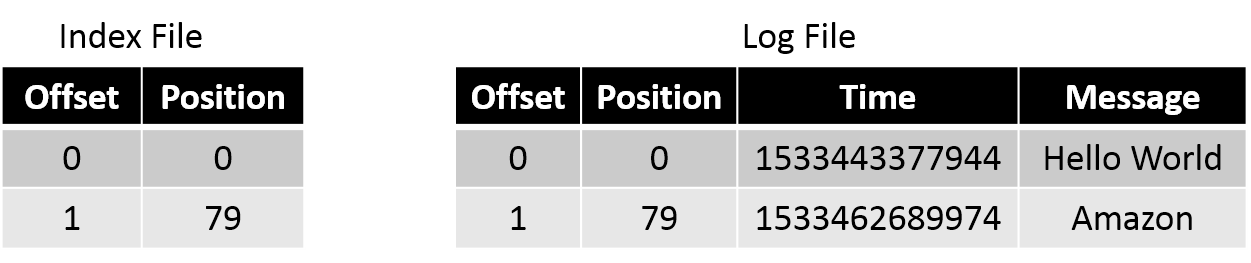
kafka-dump-log.sh 명령어를 이용해서 .log 파일을 출력할 수 있다.
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-dump-log.sh --print-data-log --files /data/kafka-logs/teki-test01-0/00000000000000000000.log# 로그 파일 출력
--print-data-log : 로그를 덤프하면서 메시지 내용을 출력
--files /data/kafka-logs/teki-test01-0/00...0.log : 덤프할 로그 파일을 지정. 콤마(,)로 구분해 여러 파일을 한 번에 읽을 수 있다.
직접 출력해보니 아까 보냈던 메시지 "test message"를 확인할 수 있었다.

# 로그 파일 내용
Starting offset: 0 : 시작 오프셋 위치가 0임
baseOffset: 0 lastOffset: 0 count: 1 : 메시지 카운드는 1임
payload: test message : 아까 보낸 메시지 "test message" 확인
같은 방법으로 다른 카프카 브로커(teki-kafka01~teki-kafka03)에서도 똑같은 데이터가 저장되어 있는 것을 확인할 수 있었다 (리플리케이션).

로그 세그먼트 관리 방법
앞에서 살펴보았듯 로그는 .log 형태로 저장되는 카프카의 세그먼트 파일을 의미한다. 카프카에 메시지가 들어오면 하나의 로그 세그먼트 파일에 덧붙이다가 segment.bytes에 설정된 크기(default: 1GB)에 도달하면 해당 세그먼트 파일을 close하고, 새로운 로그 세그먼트 파일을 생성한다(롤링Rolling). 하지만 이 파일을 무한히 쌓아둘 수는 없기 때문에 이 책에서는 로그 세그먼트를 관리하는 두 가지 방법을 소개한다.
먼저, 로그 세그먼트를 주기적으로 삭제하는 방법이 있다. 토픽 별로 로그의 보관 주기 또는 기준 크기를 설정해주면 카프카가 주기적으로 삭제 작업을 확인하여 로그 세그먼트를 삭제해준다. 체크 주기는 default 5분으로 설정되어 있고, 브로커 설정 파일(server.properties)에서 log.retension.check.interval.ms값을 바꾸면 주기를 수정할 수 있다.

두 번째 방법은 컴팩션을 이용해 로그를 삭제하지 않는 대신 압축하여 보관하는 방법이다. 컴팩션은 이 로그 세그먼트를 관리하는 카프카의 정책 중 하나로, [실습 4]에서 봤던 __consumer_offset 토픽들이 로그 컴팩션을 사용하고 있다고 한다. 로그 컴팩션은 빠른 장애 복구라는 장점이 있지만, 작업 시 브로커에 입출력 부하가 발생할 수 있기 때문에 무조건 컴팩션을 사용하는 것은 비효율적이라고 한다. 따라서 필요에 따라 로그 관리 방법을 달리하고, 컴팩션 사용 시 반드시 브로커의 리소스 모니터링을 병행해야 한다. 로그 컴팩션은 나중에 더 공부해보기로 했다.
🐣 [실습 5] 로그 세그먼트 삭제
로그의 최대 보관 시간 또는 최대 보관 용량을 설정해서 기준치를 넘어가면 삭제 명령을 내리도록 설정할 수 있다. 먼저 실습을 위해 파티션 수 1, 리플리케이션 팩터 3으로 설정한 토픽을 생성해주었다.
[1] 최대 보관 시간 설정: retention.{ms|minutes|hours} 옵션
최대 보관 시간을 설정하면 그보다 오래된 파일을 삭제한다. interval(체크 주기) 값보다 짧게 설정하면 제때 삭제하지 않을 수 있음에 주의한다.

[2] 최대 보관 용량 설정: retention.bytes 옵션
최대 보관 용량을 설정하면 그보다 용량이 커질 때 세그먼트를 삭제한다. 파티션 당 용량을 기준으로 하기 때문에 모든 브로커에 파티션이 총 N개이면 총 retention.bytes*N만큼 용량을 차지한다. 또한, 세그먼트 단위로 파일을 삭제하기 때문에 활성상태인 세그먼트 1개만 남아있는 경우, retention.bytes를 넘어가도 정상적으로 삭제되지 않을 수 있다. 따라서 segment.bytes를 retention.bytes보다 작게 설정해주어야 한다는 점에 주의한다.

[3] 조건 삭제
조건을 걸 땐 --add-config 옵션을 주었다. 반대로 설정한 조건을 삭제하려면 --delete-config 옵션을 주면 된다. 앞에서 걸어준 조건 2개를 모두 삭제해주었다. 정상적으로 삭제되면 Complete 메시지가 출력된다.

메시지 일관성 유지 전략
카프카의 가장 큰 장점 중 하나는 고가용성이다. 리플리케이션 동작을 통해 고가용성을 확보했지만, 성능에 크게 영향을 주지 않으면서 안정적으로 리플리케이션하기 위해 여러 전략을 세웠다. 리더-팔로워 구조와 이를 유지하기 위한 ISR 그룹, 그리고 리더 선출을 담당하는 컨트롤러가 있다. 또, 커밋 동작과 커밋 오프셋 위치(하이워터마크), 복구 작업 시 사용하는 리더에포크 등도 메시지 일관성을 위한 전략이다. 브로커에서 카프카 서비스를 종료해 임의로 장애를 일으켜보는 실습을 통해 카프카가 메시지 일관성을 어떻게 유지할 수 있는지 이해해보았다.
1. 리더-팔로워
카프카는 리플리케이션을 하기 때문에 일반적인 상황에서 N개의 파티션이 동일한 메시지를 가지고 있다. 메시지를 전송할 때마다 매번 모든 파티션과 통신하는 것은 매우 비효율적이다. 따라서 카프카는 각 토픽을 중심으로 리플리케이션을 하고 있는 파티션들의 그룹에서 리더를 선발해서 프로듀서와 컨슈머는 리더를 통해서만 읽기/쓰기 작업을 수행하고, 나머지 팔로워들은 리더로부터 읽기 작업만 수행할 수 있도록 했다.
아래 그림은 브로커 4대에 파티션을 분배한 구조를 도식화한 것이다. 만약 리플리케이션 팩터를 1로 설정해서 복제본이 없다면, 왼쪽과 같이 3개 파티션만 존재할 것이다. 리플리케이션 팩터를 3으로 설정한다면, 카프카에는 오른쪽 그림과 같이 9개 파티션이 존재하게 된다. 총 파티션 수는 다르지만, 컨슈머와 프로듀서 사이에서 메시지를 읽고 쓰는 작업을 수행하는 파티션(리더)은 양쪽 모두 3개로 동일하다. 오른쪽의 경우 리더가 메시징 작업을 하는동안 나머지 파티션(팔로워: R1,R2)은 리더로부터 메시지를 읽어온다. 왼쪽 케이스는 브로커에 장애 발생 시 복불복으로 데이터 유실이 생기지만, 오른쪽 케이스는 브로커 중 하나에서 장애가 발생하더라도 다른 브로커에 복제본이 있어 메시지를 보존할 수 있는 걸 그림에서 확인할 수 있다.


2. ISR과 컨트롤러
위 그림 중 오른쪽 케이스에서 리더 파티션이 있는 브로커에 장애가 발생했다면, 나머지 두 파티션 중 하나가 리더의 역할을 물려받아야 한다. 하지만 적절한 후보를 리더로 선출하지 않으며 메시지에 누락이 생기거나 또다른 장애가 발생할 수 있다. 그래서 리더와 리더가 될 자격이 있는 후보를 관리하기 위한 논리적인 그룹인 ISRInSyncReplica과 이를 관리하는 컨트롤러의 역할이 팔요해진다.
리플리케이션 팩터 수만큼 파티션을 복제한다고 했다. 이때, 한 파티션에 대한 복제본 중 가용한 파티션은 모두 ISR에 속한다. 즉, ISR에 속한 파티션은 리더이거나 리더가 될 자격이 있는 팔로워이다. 리더가 될 자격이 있다는 것은 리더와 동일한 데이터를 가지고 있음을 보장할 수 있다는 것을 의미한다. 자격을 상실한 파티션은 ISR에서 추방한다.
아래 그림은 장애 발생 시 ISR의 변화를 나타낸다. 만약 팔로워 파티션에 장애가 발생하면 ISR에서 추방한다(붉은색-topic02). 만약 리더 파티션에서 장애가 발생하면 ISR에서 리더를 퇴출하고 그룹 내 팔로워 중 하나를 새로운 리더로 선출한다(푸른색-topic01). 현재 ISR에 대한 정보는 [실습 2]에서와 같이 kafka-topics.sh 명령어에 describe 옵션을 주어 확인할 수 있다.



만약 ISR를 가진 브로커가 없다면 복구가 불가능한 상황이 되어 서비스 중단이 된다. 이 경우, 카프카는 OSROut-ofSyncReplica를 사용할 수 있다. OSR은 ISR 리스트에 없는 파티션을 리더로 선출할 수 있도록 하는 방식이며, unclean.leader.election.enable 옵션으로 사용여부를 설정할 수 있다. 해당 옵션값이 true로 설정되어 있다면 ISR을 가진 브로커가 없는 경우, ISR이 아닌 파티션 중에서 리더를 선발할 수 있다. 이는 리더가 될 자격을 보장할 수 없는(Unclean) 팔로워를 리더로 선출함으로 인한 데이터 유실 위험을 감수하고 서비스 중단의 위험성을 줄이는 방법이다.
카프카 옵션 중 min.insync.repliacs는 프로듀서가 카프카로 메시지 전송 시 write 성공을 보장할 수 있는 최소 복제본의 수(default: 1)를 의미한다. 즉, 프로듀서는 카프카에 메시지를 전송하고, min.insync.repliacas 이상의 팔로워가 리더로부터 복제를 완료하면 메시지 전송에 성공했다고 판단한다. 따라서 리플리케이션 팩터가 3이었지만 장애 발생으로 ISR에서 리플리케이션을 수행하는 파티션이 2개만 남았다고 해도 최소 복제본 수 1을 충족할 수 있다면 정상적으로 통신이 가능하다. 단, 메시지 전송 성공 확인 이후라도 남은 파티션에 복제가 실패하면 ISR에서 추방될 수 있다.
이런 경우를 방지하기 위해 리플리케이션 팩터 개수와 최소 복제본 수를 같게 설정하고 싶을 수 있다. 만약 위 사진의 topic02와 같은 상황에서 min.insync.replicas를 리플리케이션 팩터와 동일하게 3으로 설정했다면, 아무리 메시지를 전송하고 복제를 시도해도 최대 파티션이 2개를 넘지 못하기 때문에 프로듀서는 메시지 전송에 항상 실패하게 된다. 이렇듯 topic.replication.factor와 min.insync.replicas를 동일하게 설정하면, 장애 발생 시 바로 카프카 브로커 다운으로 이어진다. 따라서 필요에 따라 적정한 값을 설정해주는 것이 중요하겠다. 카프카에서는 topic.replication.factor=3, min.insync.replicas=2를 권장한다고 한다.
이렇게 ISR를 유지하고, 장애 발생 시 팔로워 중 리더를 선출하는 일은 모두 컨트롤러가 담당한다. 카프카 클러스터 중 하나의 브로커가 컨트롤러 역할을 하며, ISR의 데이터는 가용성을 보장하기 위해 주키퍼에 저장한다. (주키퍼가 없는 버전에서는?)
🐣 [실습 6] controlled shutdown 설정
컨트롤러가 새로운 리더를 선출해야 하는 종료 상황은 크게 두 가지로 분류한다. 하나는 예기치 않은 장애나 실패로 인한 종료 상황이고, 다른 하나는 controlled shutdown이라고 하는 graceful shutdown 또는 안전한 종료에 해당하는 종료 상황이다. controlled shutdown의 경우, 브로커의 모든 로그를 디스크에 동기화한 후 종료한다. 이후 브로커 재시작 시 로그 복구 시간이 짧다는 장점이 있으나 새로운 리더 선출에 따른 downtime이 있는데, kafka 1.0.0 버전에서 6분 30초 걸리던 작업을 kafka 1.1.0 버전에서는 3초로 줄였다고 한다. 이 설정은 server.properties에서 cotrolled.shudown.enable 옵션 (true일 때 controlled) 또는 kafka-config.sh 명령어로 확인할 수 있다.
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-configs.sh --bootstrap-server teki-kafka01.foo.bar:9092 --broker 1 --describe --all# 현재 브로커 설정 확인
--bootstrap-server teki-kafka01.foo.bar:9092 : 대상 브로커가 있는 서버의 호스트 및 포트 지정
--broker 1 : 1번 브로커를 지정하여 조회
--describe --all : 설정 정보 전체를 조회
모든 설정 정보가 다 나와서 그 중 controlled.shutdown 설정만 찾아봤더니 3개나 나왔다.

# controlled.shutdown 관련 브로커 설정 정보
controlled.shutdown.enable=true : 제어된 종료 사용 여부(true: 사용함)
controlled.shutdown.max.retries=3 : 제어된 종료 실패 시 재시도 횟수
controlled.shutdown.retry.backoff.ms=5000 : 제어된 종료 실패로 재시도하기 전, 이전 실패 복구를 위해 대기하는 시간(단위: ms)
3. 하이워터마크(커밋)와 리더에포크
카프카 파티션은 메시지를 저장하고, 그 위치를 오프셋으로 기억한다. 프로듀서가 리더에게 새로운 메시지를 보내고 ISR 내에서 모든 팔로워의 복제가 완료되면, 리더는 내부적으로 모든 리플리케이션 팩터가 전부 메시지를 복제했다는 표시(커밋)을 한다. 컨슈머는 커밋된 메시지만 읽을 수 있다. 단, 프로듀서 설정과 관련된 min.insync.replicas 설정값은 컨슈머에 영향을 주지 않는다.
마지막으로 커밋을 완료한 오프셋 위치를 하이워터마크라고 하며, 각 파티션마다 하이워터마크 정보를 저장하고 있다. 리더가 예상치 못한 장애로 다운되면, 새로운 리더로 선발된 (구)팔로워는 복구 과정에서 자신의 하이워터마크보다 높은 메시지를 삭제한다. 하지만 메시지를 저장하고 하이워터마크를 갱신하는 동작이 동시에 이루어지지 않기 때문에 메시지 손실이 발생할 수 있다. 따라서 리더에포크를 추가로 적용한다.
리더에포크를 적용하면 장애에서 복구된 팔로워가 메시지 삭제 동작을 하기 전에 먼저 리더에포크 요청과 응답 과정을 통해 하이워터마크를 갱신하여 메시지 손실을 방지할 수 있다. 말로는 잘 이해가 되지 않아서 자세한 동작은 실습을 통해 알아보았다.
🐣 [실습 7] 하이워터마크 확인
하이워터마크는 로컬 디스크의 replication-offset-checkpoint라는 파일에 저장돼있어 직접 확인할 수 있다. [실습 4]에서 확인한 /data/kafka-logs 하위에 있는 파일 중 replication-offset-checkpoint 파일이 있었다. 사람이 읽을 수 있는 파일이므로 cat으로 확인해보았다.
[yt.lim@teki-kafka01 ~]$ cat /data/kafka-logs/replication-offset-checkpoint
0
52
__consumer_offsets 29 0
__consumer_offsets 43 3
__consumer_offsets 0 0
__consumer_offsets 6 3
...
__consumer_offsets 34 0
__consumer_offsets 9 3
__consumer_offsets 14 0우선 두 번째 줄은 오프셋 정보가 총 52줄이 있다는 것을 의미한다는 것은 알겠다. 우선 이 중 지금 필요한 줄만 뽑아보았다.

띄어쓰기를 기준으로 왼쪽부터 순서대로 토픽 이름, 파티션 번호, 커밋된 오프셋 번호를 뜻한다고 한다. 현재 teki-test01는 [실습 4]에서 보낸 테스트 메시지 이후 "Hi"라고 한 번 더 보낸 상태이니 커밋된 오프셋 번호가 오프셋이 2가 맞다. 새로 메시지를 보내 정말 변하는지 다시 확인해보았더니 대략 2초정도 후에 커밋이 완료되어 오프셋이 2에서 3으로 바뀌었다.

다른 브로커에도 동시에 변하는지 궁금해서 한 번 더 메시지를 보내보았다.

🐣 [실습 8] 리더에포크 확인
리더에포크 상태는 리더의 leader-epoch-checkpoint 파일에 저장된다. teki-test01 토픽의 리더인 1번 브로커에 가서 파일을 열어보았다.

# 리더에포크 정보
0 : 파티션 번호
1 : 현재의 리더에포크 번호
0 0 : 첫 번째 0은 리더에포크 번호, 두 번째 0은 최종 커밋 후 새로운 메시지를 전송받게 될 오프셋 번호 (s"${entry.epoch} ${entry.startOffset}")
이렇게 리플리케이션과 장애 복구 과정 등 카프카의 내부 동작 원리를 알아보았다. 카프카 명령어를 사용해보는 실습이 많았는데, 직접 해본 만큼 카프카에 대해 훨씬 많이 알게 된 것 같다. 특히, 카프카를 더 효율적으로 운영하기 위해 고민할 수 있도록 이해의 기반을 다지는 내용이라 더 많은 시간을 투자한 것 같다. 대신 로그 컴팩션은 이번에는 존재만 알고 넘어가고, 다음에 더 자세히 공부해보려고 한다. 임의로 장애 상황을 만들어서 리더에포크 상태 변화를 확인하는 실습은 더 테스트해보고 따로 포스팅하기로 했다. 다음 장에서는 프로듀서에 관해 공부할 예정이다.
※ Kafka Study 순서 ※
01. 카프카 특징과 이용 사례
02. 카프카 기본 개념과 구조
03. 카프카 실습 환경 구성 및 프로듀서와 컨슈머 기본동작과 예제
04. 카프카의 내부 동작 원리와 구현
05. 프로듀서의 내부 동작 원리와 구현
06. 컨슈머의 내부 동작 원리와 구현
07. 카프카 운영과 모니터링
08. 카프카 버전 업그레이드와 확장
09. 카프카 보안
10. 스키마 레지스트리
11. 카프카 커넥트
12. 엔터프라이즈 카프카 아키텍처 구성 사례
13. 카프카의 발전과 미래
※ 참고 자료 ※
[1] 실전 카프카 개발부터 운영까지, http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9791189909345#N
[2] 아파치 카프카 애플리케이션 프로그래밍 with 자바, http://www.kyobobook.co.kr/product/detailViewKor.laf?
[3] Kafka 운영자가 말하는 Topic Replication, https://www.popit.kr/kafka-%EC%9A%B4%EC%98%81%EC%9E%90%EA%B0%80-%EB%A7%90%ED%95%98%EB%8A%94-topic-replication/
[4] Kafka 운영자가 말하는 Producer ACKS, https://www.popit.kr/kafka-%EC%9A%B4%EC%98%81%EC%9E%90%EA%B0%80-%EB%A7%90%ED%95%98%EB%8A%94-producer-acks/
[5] https://github.com/apache/kafka/blob/ba237c5d21abb8b63c5edf53517654a214157582/core/src/main/scala/kafka/server/epoch/LeaderEpochFileCache.scala#L42
[6] what is a role of leader epoch checkpoint in log segment of Kafka partition?, https://stackoverflow.com/questions/50342961/what-is-a-role-of-leader-epoch-checkpoint-in-log-segment-of-kafka-partition
[7] [Kafka] 카프카 튜토리얼_Quick Start, https://soyoung-new-challenge.tistory.com/61
[8] https://docs.confluent.io/platform/current/installation/configuration/topic-configs.html
[9] what are the different logs under kafka data log dir, https://stackoverflow.com/questions/53744646/what-are-the-different-logs-under-kafka-data-log-dir
[10] Kafka retention 옵션 - log 보관 주기 설정, https://deep-dive-dev.tistory.com/63
[11] Kafka Replication, https://damdam-kim.tistory.com/17
[12] [Kafka] acks와 min.insync.replicas, https://songhayoung.github.io/2020/07/13/kafka/acks-replicas/#Introduction
[13] cloudera - ISR management, https://docs.cloudera.com/cdp-private-cloud-base/7.1.6/kafka-performance-tuning/topics/kafka-tune-broker-tuning-isr.html
[14] [kafka] unclean.leader.election.enable 옵션, https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=freepsw&logNo=221028179182
[15] Apache Kafka Supports 200L Partitions Per Cluster, https://www.confluent.io/blog/apache-kafka-supports-200k-partitions-per-cluster/
[16] Kafka Broker Configurations, https://docs.confluent.io/platform/current/installation/configuration/broker-configs.html
[17] Apache Kafka: Topic Partitions, Replicas & ISR, https://blog.knoldus.com/apache-kafka-topic-partitions-replicas-isr/
'Tech > Data Processing' 카테고리의 다른 글
| [Kafka Study] 05. 프로듀서의 내부 동작 원리와 구현 w/실전 카프카 개발부터 운영까지 (0) | 2022.04.08 |
|---|---|
| [Kafka Study] 03. 카프카 실습 환경 구성 및 프로듀서와 컨슈머 기본 동작과 예제 w/실전 카프카 개발부터 운영까지 (6) | 2022.03.07 |
| [Kafka Study] 02. 카프카 기본 개념과 구조 w/실전 카프카 개발부터 운영까지 (0) | 2022.03.04 |
| [Kafka Study] 01. 카프카 특징과 이용 사례 w/실전 카프카 개발부터 운영까지 (0) | 2022.03.01 |



