
테키테크 TEKITECH
[Kafka Study] 03. 카프카 실습 환경 구성 및 프로듀서와 컨슈머 기본 동작과 예제 w/실전 카프카 개발부터 운영까지 본문
[Kafka Study] 03. 카프카 실습 환경 구성 및 프로듀서와 컨슈머 기본 동작과 예제 w/실전 카프카 개발부터 운영까지
TEKI 2022. 3. 7. 19:50이번 장에서는 카프카 실습을 위해 인프라 구축을 해본다. 책에서 추천하는 방법은 AWS 환경이고, 온프레미스로 구축하는 방법도 알려준다. 하지만 나는 GCP를 사용하고 있기 때문에 GCP에서 실습을 진행했다. 환경을 구축한 후에는 프로듀서와 컨슈머에서 메시지를 주고받는 동작을 실제로 해보면서 기본 구동 원리를 공부했다.

실습 환경 구성
책에서는 카프카 3대, 주키퍼 3대, 배포용 서버 1대와 DNS 서버 1대로 구축해보는 것을 추천한다. 하지만 테스트용이므로 DNS 서버 구축까지는 안 하고 호스트 파일만 바꿔주기로 했다. 그래서 내가 구축하려는 환경은 아래와 같다. 어느 정도 익숙해지면 DNS 서버 두고 사이즈를 좀 더 키워보고 싶다.

GCP VM 인스턴스 스펙과 예상 비용
책에서 권장하는 주키퍼와 카프카 인스턴스의 최소 사양은 CPU 2, 4GB MEM이다. 그리고 배포용 서버는 그보다 낮아도 된다고 했다. 그래서 e2-medium(CPU 2, 4GB MEM) 6대와 e2-small(CPU 2, 2GB MEM) 1대를 생성하기로 했다. 그리고 리전 별로 비용이 상이한데 그중 가장 저렴한 편인 us-central1(아이오와)로 지정해주었다. OS는 책에서 Amazon Linux2와 가장 유사하다는 CentOS 7을 사용하면 된다고 해서 이걸로 부팅디스크를 만들어주었다.

네트워크 설정
이제 호스트 파일을 수정해야 한다. 책에서 알려준 것과 동일하게 7개 인스턴스의 내부 IP에 인바운드 규칙과 foo.bar 도메인을 매핑하여 7개 인스턴스의 호스트 파일을 모두 수정해주었다. (참고: 카프카에서 internal traffic과 exernal traffic 분리 및 /etc/hosts 파일 설정)
10.128.0.23 teki-ansible01.foo.bar teki-ansible01
10.128.0.16 teki-kafka01.foo.bar teki-kafka01
10.128.0.17 teki-kafka02.foo.bar teki-kafka02
10.128.0.18 teki-kafka03.foo.bar teki-kafka03
10.128.0.19 teki-zk01.foo.bar teki-zk01
10.128.0.20 teki-zk02.foo.bar teki-zk02
10.128.0.21 teki-zk03.foo.bar teki-zk03
그다음 서로 잘 통신이 되는지 확인해보았다.
ping -c 2 teki-ansible01.foo.bar
ping -c 2 teki-kafka01.foo.bar
ping -c 2 teki-kafka02.foo.bar
ping -c 2 teki-kafka03.foo.bar
ping -c 2 teki-zk01.foo.bar
ping -c 2 teki-zk02.foo.bar
ping -c 2 teki-zk03.foo.bar
실습 소스 코드
이 책에서 실습하는 소스 코드는 깃에 올라가 있다. 코드를 다운로드하자.
$ sudo yum install -y git
$ git clone https://github.com/onlybooks/kafka2
앤서블Ansible 설치
카프카와 주키퍼 서버를 최소 3대씩 운영해야 하기 때문에 배포 자동화 도구가 필요하다. 앤서블은 오픈소스 소프트웨어로서, 다수의 서버를 대상으로 설정 관리, 애플리케이션 배포 등을 코드로 관리할 수 있도록 도움을 주는 도구라고 한다. 앤서블은 사용법이 간단해서 1인 관리자가 많이 사용한다고 한다. teki-ansible01에 앤서블을 설치해주자.
$ sudo yum install epel-release
$ sudo yum install ansible
주키퍼 설치
이제 teki-ansible01에 가서 앤서블로 주키퍼를 설치할 차례다. 깃에서 다운로드한 경로에서 chapter 2에 가면 ansible_playbook 디렉토리가 있다. 예제에서는 peter-xx로 되어있는데 내가 만든 서버는 teki-xx이기 때문에 설정 파일에서 도메인 이름과 서버 이름을 모두 바꿔줘야 한다. hosts 파일과 yaml파일, 그 외 여러 파일에서 peter를 모두 찾아 teki로 바꾸어준다. 그다음 ansible-playbook 명령어와 zookeeper.yml로 hosts 파일에 지정된 서버에 주키퍼를 설치해준다.
# 수정한 hosts 파일
[yt.lim@teki-ansible01 ansible_playbook]$ cat hosts
[zkhosts]
teki-zk01.foo.bar
teki-zk02.foo.bar
teki-zk03.foo.bar
[kafkahosts]
teki-kafka01.foo.bar
teki-kafka02.foo.bar
teki-kafka03.foo.bar
[kerberoshosts]
teki-zk01.foo.bar
# hosts 파일에 지정된 서버에 zookeeper.yml에 정의한 동작(주키퍼 설치)을 수행한다.
[yt.lim@teki-ansible01 ansible_playbook]$ ansible-playbook -i hosts zookeeper.yml
설치 끝.

주키퍼가 잘 올라갔는지 서버에 들어가서 확인해준다.
[yt.lim@teki-zk01 ~]$ sudo systemctl status zookeeper-server
[yt.lim@teki-zk02 ~]$ sudo systemctl status zookeeper-server
[yt.lim@teki-zk03 ~]$ sudo systemctl status zookeeper-server
카프카 설치
카프카도 주키퍼와 같은 방식으로 설치해준다.
# hosts 파일에 지정된 서버에 zookeeper.yml에 정의한 동작(주키퍼 설치)을 수행한다.
[yt.lim@teki-ansible01 ansible_playbook]$ ansible-playbook -i hosts kafka.yml
카프카가 잘 올라갔는지 확인해준다.
[yt.lim@teki-kafka01 ~]$ sudo systemctl status kafka-server
[yt.lim@teki-kafka02 ~]$ sudo systemctl status kafka-server
[yt.lim@teki-kafka03 ~]$ sudo systemctl status kafka-server
설치 끝! ft. Ansible로 주키퍼와 카프카를 설치하면서 헤맸던 기록
메시징 테스트
위에서 구성한 카프카에서 1) 토픽을 생성하고, 2) 콘솔 프로듀서와 콘솔 컨슈머로 메시지를 주고받는 테스트를 해보았다.
1. 토픽 생성
카프카가 설치된 서버에서 카프카가 제공하는 도구 중 kafka-topics.sh 명령어를 이용해 teki-overview01 토픽을 생성했다.
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server teki-kafka01.foo.bar:9092 --create --topic teki-overview01 --partitions 1 --replication-factor 3
성공하면 토픽이 생성되었다는 메시지가 출력된다. 메시지를 보내고 받을 준비가 끝났다.
Created topic teki-overview01.
2. 프로듀서와 컨슈머로 메시지 주고받기
테스트를 위해 같은 서버에서 프로듀서 cmd 창과 컨슈머 cmd 창을 각각 하나씩 열고, 아래 명령어를 실행해주었다.
# 프로듀서
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-console-producer.sh --bootstrap-server teki-kafka01.foo.bar:9092 --topic teki-overview01
# 컨슈머
[yt.lim@teki-kafka01 ~]$ /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server teki-kafka01.goo.bar:9092 --topic peter-overview01
프로듀서 창은 메시지를 전송할 수 있는 명령 프롬프트로 바뀐 것을 확인했고, 컨슈머 창은 아직 전송한 메시지가 없으므로 아무것도 출력되지 않는 화면인 걸 확인했다. 이 상태에서 프로듀서에 메시지를 입력해주면 컨슈머에서 메시지를 받아서 출력해준다. 컨슈머를 종료하면 받은 메시지 개수를 알려주기도 한다.

프로듀서 기본 동작과 예제
위 실습에서 프로듀서는 메시지 전송을 담당했다. 실제로 프로듀서는 여러 옵션으로 다양한 메시지 전송 방식을 구현할 수 있다. 프로듀서의 메시지 구조와 전송 로직, 그리고 옵션에 대해 알아보았다.
프로듀서 전체 흐름
프로듀서의 전체 흐름은 아래와 같다. 실제 메시지 데이터인 ProducerRecord, 메시지를 전송하는 프로듀서의 send() 메소드, 그리고 send() 메소드 동작 이후 카프카에 전송되기 전까지 벌어지는 일들에 대해 알아보았다.

Producer Record
프로듀서가 카프카로 전송하는 실제 메시지는 ProducerRecord이다. 이 레코드는 토픽과 파티션, 그리고 키와 밸류로 구성되어 있다.
[1] 토픽 (필수)
프로듀서가 카프카로 레코드를 전송할 때, 카프카의 특정 토픽으로 메시지를 전송한다. 따라서 레코드에는 대상 토픽 정보가 필수적으로 들어있다.
[2] 파티션 (선택)
기본적으로 라운드 로빈 방식으로 파티션을 선택해 레코드를 전달한다. 또는 특정 토픽의 특정 파티션을 지정하여 레코드를 전송할 수 있는데, 이때 '파티션' 값을 레코드에 넣어준다.
[3] 키 (선택)
대상 파티션을 지정할 때, 파티션에 레코드를 정렬할 수 있는 키를 함께 전달할 수 있다.
[4] 밸류 (필수)
메시지의 내용이다. 당연히 필수.
send() 메소드와 배치 전송
레코드는 send() 메소드를 통해 카프카로 전송을 시작하고, 시리얼라이저Serializer와 파티셔너Partitioner를 거쳐 파티션 별로 모여 대기한다. 이후 카프카로 배치 전송을 시도한다. 만약 배치 전송에 실패하면 지정된 재시도 횟수만큼 다시 send() 메소드 실행 전으로 돌려보내는 재시도 동작을 수행하고 성공 시 레코드와 메타데이터를, 실패 시 최종 실패를 전달한다.
프로듀서의 주요 옵션
프로듀서의 주요 옵션은 아래와 같다.

컨슈머 기본 동작과 예제
프로듀서에서 메시지를 전송했다면, 컨슈머에서 메시지를 받을 수 있다. 컨슈머는 내부적으로 컨슈머 그룹Consumer Group, 리밸런싱Rebalancing 등 여러 동작을 수행한다. 프로듀서의 속도와 비슷한 수준으로 컨슈머에서 메시지를 읽고 처리해야 지연이 발생하지 않기 때문에 이러한 동작들이 중요하다고 한다.
컨슈머의 기본 동작
프로듀서가 카프카의 토픽으로 메시지를 전달했다면, 그 메시지들은 브로커의 로컬 디스크에 저장된다. 컨슈머가 가져오는 메시지들은 그 데이터다.
[1] 컨슈머 그룹
카프카의 파티션에 메시지를 요청하는 주체는 컨슈머 그룹이다. 컨슈머 그룹은 하나 이상의 컨슈머들이 모여 있는 그룹을 의미하는데, 모든 컨슈머는 반드시 어떠한 컨슈머 그룹에 속한다. 컨슈머 그룹은 파티션의 리더에게 메시지를 요청하느데, 이때 파티션 수와 컨슈머 그룹 내 컨슈머의 수는 일대일로 매칭되는 것이 이상적이라고 한다. 파티션 수보다 컨슈머 수가 많으면, 노는 컨슈머가 늘어나서 비효율적이기 때문이다.
[2] 리밸런싱
만약 파티션에 메시지를 요청한 컨슈머 그룹 내에서 일부 컨슈머에 장애가 발생했다면, 리밸런싱 동작을 통해 동일한 그룹에 있는 다른 컨슈머가 역할을 대신 수행한다.
컨슈머가 메시지를 가져오는 방법 세 가지
컨슈머가 메시지를 가져오는 방법은 크게 1) 오토 커밋, 2) 동기 가져오기, 3) 비동기 가져오기의 세 가지 방식이 있다.
[1] 오토 커밋
오토 커밋은 오프셋을 주기적으로 커밋해주는 방식이다. 관리자가 오프셋을 따로 관리하지 않아도 되어 편리하기 때문에 컨슈머 애플리케이션들의 기본값으로 가장 많이 사용된다. 메시지 누락이나 중복 등 문제가 생기는 경우가 있지만 일반적인 상황에서는 거의 발생하지 않고 안정적으로 동작한다고 한다.
[2] 동기 가져오기
poll()을 이용해 메시지를 가져와 처리를 완료한 다음 현재 오프셋을 커밋한다. 그만큼 속도는 느리지만, 잘못된 오프셋 커밋으로 인한 메시지 손실은 거의 없다. 하지만 메시지 중복 이슈에서 자유롭지는 않다.
[3] 비동기 가져오기
오프셋 커밋에 실패해도 재시도하지 않기 때문에 메시지 누락 위험은 있지만, 메시지 중복 이슈에서 상대적으로 가장 자유롭다. 이러한 비동기 방식을 보완하기 위해 콜백을 같이 사용하는 경우도 있다.
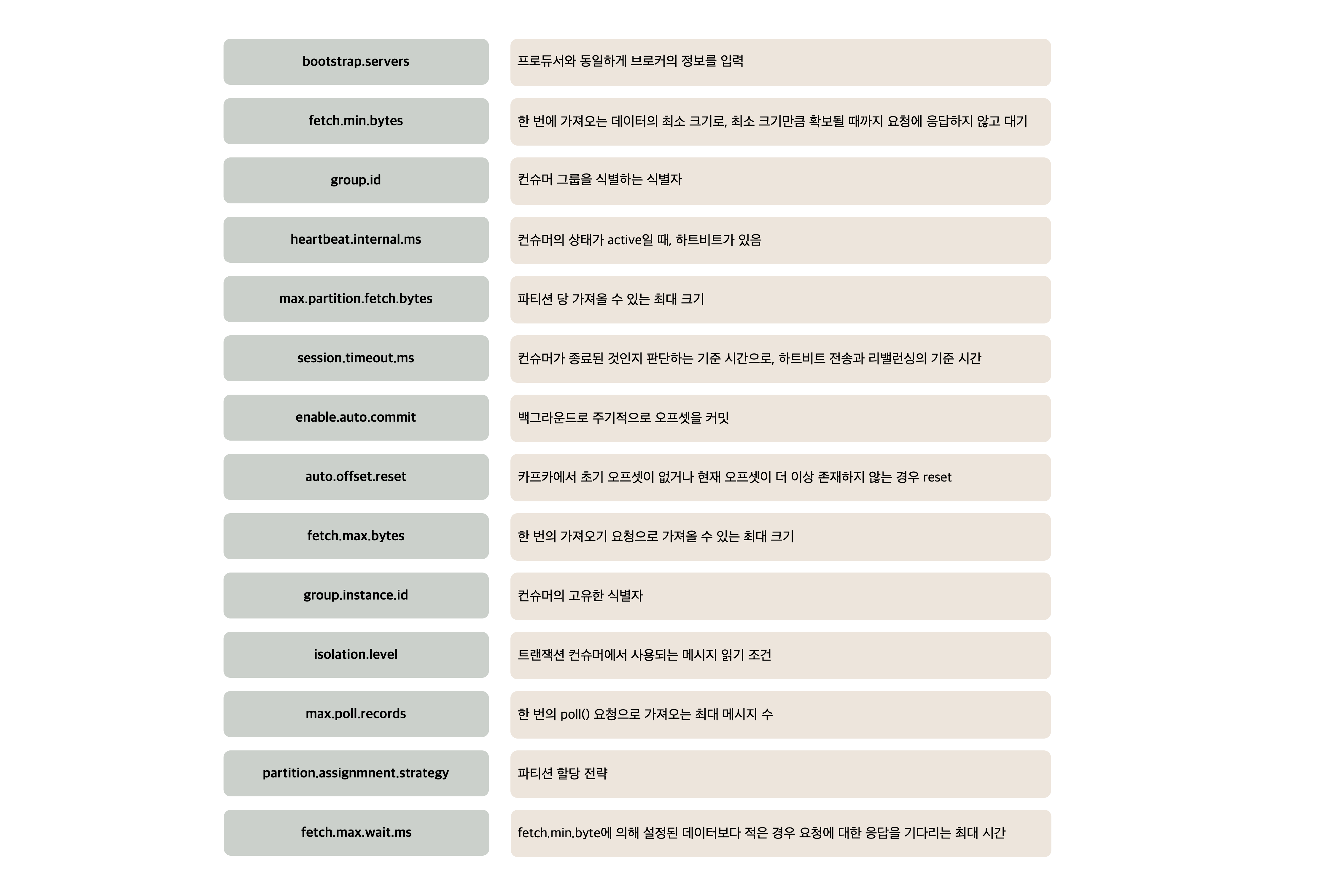
컨슈머의 주요 옵션
컨슈머의 주요 옵션은 아래와 같다.
※ Kafka Study 순서 ※
01. 카프카 특징과 이용 사례
02. 카프카 기본 개념과 구조
03. 카프카 실습 환경 구성 및 프로듀서와 컨슈머 기본 동작과 예제
04. 카프카의 내부 동작 원리와 구현
05. 프로듀서의 내부 동작 원리와 구현
06. 컨슈머의 내부 동작 원리와 구현
07. 카프카 운영과 모니터링
08. 카프카 버전 업그레이드와 확장
09. 카프카 보안
10. 스키마 레지스트리
11. 카프카 커넥트
12. 엔터프라이즈 카프카 아키텍처 구성 사례
13. 카프카의 발전과 미래
※ 참고 자료와 이미지 출처 ※
'Tech > Data Processing' 카테고리의 다른 글
| [Kafka Study] 05. 프로듀서의 내부 동작 원리와 구현 w/실전 카프카 개발부터 운영까지 (0) | 2022.04.08 |
|---|---|
| [Kafka Study] 04. 카프카의 내부 동작 원리와 구현 w/실전 카프카 개발부터 운영까지 (0) | 2022.03.28 |
| [Kafka Study] 02. 카프카 기본 개념과 구조 w/실전 카프카 개발부터 운영까지 (0) | 2022.03.04 |
| [Kafka Study] 01. 카프카 특징과 이용 사례 w/실전 카프카 개발부터 운영까지 (0) | 2022.03.01 |



